Most production-grade applications we see have grown the same way: development happened first, DevOps was added later, and operations was the team that picked up the pieces after launch. That sequencing produces working systems, but it also produces an enduring tax. Logging gets added after the first outage. Authentication gets re-architected after the first audit. Deployment becomes a separate skill set rather than a property of the architecture.
We have spent the last few years shaping production platforms from a different starting point. Across two recent builds — a fullstack application platform and a cross-platform SaaS administration product — the same five principles produced systems that are visibly easier to operate, audit, and extend. This piece names those principles and shows what they look like in practice. They are not novel; they are deliberately practical.
The problem with sequential thinking
The sequence development → DevOps → operations creates predictable failure modes:
- Logging is too thin. It was added when the first incident exposed the gap. Coverage is uneven; some services log richly, others do not log at all.
- Authentication is fragmented. Each service was built with its own auth assumption, then partially harmonised under a federation layer that does not actually own anything.
- Deployment is a runbook. It works when the senior engineer is online; it fails when she is not. Staging does not actually mirror production. The first time a new starter deploys, something breaks.
- Operations is reactive. The team runs the system but does not own the architecture. Decisions made in development create operational cost the development team never sees.
The systems that age well treat development, DevOps, and operations as one design problem. The architecture map and the operating map are the same map. The five principles below are how that map gets drawn.
Principle 1: Separate the edge from the live application platform
The first decision is where the static surface ends and the live application platform begins.
Marketing pages, portfolio sites, public documentation, and content-delivery surfaces have very different operating profiles from APIs, background workers, identity providers, and databases. The static surface optimises for cost, speed, and global distribution. The live platform optimises for stability, security, and observability. Putting them on the same infrastructure makes both worse: the static surface inherits operational complexity it does not need, and the live platform inherits cache-invalidation problems it should not have.
In one of the platforms we shaped recently, the static portfolio site lives behind a content delivery network — a Cloudflare edge — with HTTPS termination and origin protection. The live application platform sits on a separate orchestrated runtime with its own identity, network, and observability stack. They share a domain root but nothing else. Deployment of the static surface is a simple build-and-publish; deployment of the live platform is a validated multi-stage pipeline. Each is right-sized for what it actually does.
The pattern: edge for content, platform for application. They should not share operating discipline because they should not have the same operational characteristics.
Principle 2: Separate services by responsibility, not by technology
The second decision is where the seams between services go.
The wrong default — and a tempting one — is to organise services by technology: a frontend service, a backend service, a database service. The right default is to organise by responsibility: what does this service own, who depends on it, and when does it need to change?
In the fullstack platform we shaped, the application layer split into five distinct services: a frontend that owns the user-facing experience, an API that owns the contract with the frontend and other consumers, a set of background workers that own asynchronous job processing, an importer that owns content ingestion and validation, and an operations monitor that owns the dashboards and read-only views into platform health. Each service has its own deployment cadence. Each can be operated, debugged, and replaced independently. Each has an obvious answer to the question “who breaks if this changes?”.
The technology stack happens to be Next.js for the frontend and NestJS for the API and workers. That is incidental. The architecture would still be five services if the technology choices were different — because the responsibilities are five things, not four or seven.
Principle 3: Treat the delivery pipeline as architecture
The third decision is the most underdone in the platforms we get called in to recover. The delivery pipeline — CI/CD — is not a final-step add-on. It is the contract that converts source code into validated, packaged, environment-promoted runtime.
A delivery pipeline that has been designed alongside the architecture has a few visible properties:
- A single source of truth. One repository structure, one merge flow, one validation gate. Pipeline configuration is in version control alongside the application code.
- Validation gates that match the architecture. If the platform has a database with schema migrations, the pipeline validates schema integrity. If there are background workers with runtime contracts, the pipeline validates those. The validation is service-shaped, not generic.
- Packaging as architecture. Successful runs produce deployment-ready artefacts — typically container images — that become the standard runtime units. Local, staging, and production all run the same artefact, just configured differently.
- Environment promotion by policy. Promoting an artefact from staging to production is a policy decision, enforced by the pipeline. It is not a manual deployment that happens to mirror staging.
In our fullstack platform, a GitLab CI/CD pipeline sits at the centre of delivery. Every commit validates the monorepo through linting, type checks, tests, and package builds. Backend stages validate the database schema and importer logic against runtime contracts. Successful runs produce Docker images that become the standard runtime. The pipeline is the same shape for local, staging, and production-style environments — only the deployment target differs.
This is not a tooling argument. The same pattern works on GitHub Actions, Azure DevOps, Jenkins, or any modern CI/CD platform. The argument is that the delivery pipeline is part of the platform’s architecture, not a separate concern handed to a different team.
Principle 4: Make observability first-class from the foundation
The fourth decision is whether observability is a service in the architecture or a layer added afterwards.
A platform with first-class observability has health, metrics, logs, and alerts as part of its architecture map. The operations monitor is a service, not a tool added by the SRE team. There is a defined home for system uptime data, service health checks, application metrics, centralised logging, and alert routing. Each of these has an owner and a cadence.
In the fullstack platform we shaped, observability shows up in the architecture diagram as its own labelled section: System Monitor for uptime and resources, Health for service-level checks, Metrics through a Prometheus-equivalent, Logs through centralised aggregation, and Alerts through an alert manager that routes to humans. These are not implementation details. They are platform capabilities that the rest of the architecture depends on.
The pattern matters because observability that is bolted on after launch is structurally weaker. Coverage is uneven, ownership is ambiguous, and the data you need at 3 AM was not collected because the service that produced it was not configured to emit it. Observability designed into the foundation produces the data you need before you know you need it.
There are no special technology choices here. Prometheus, Grafana, Datadog, Microsoft Sentinel, ELK, OpenTelemetry — all valid. The architectural decision is to treat observability as a service rather than a tool.
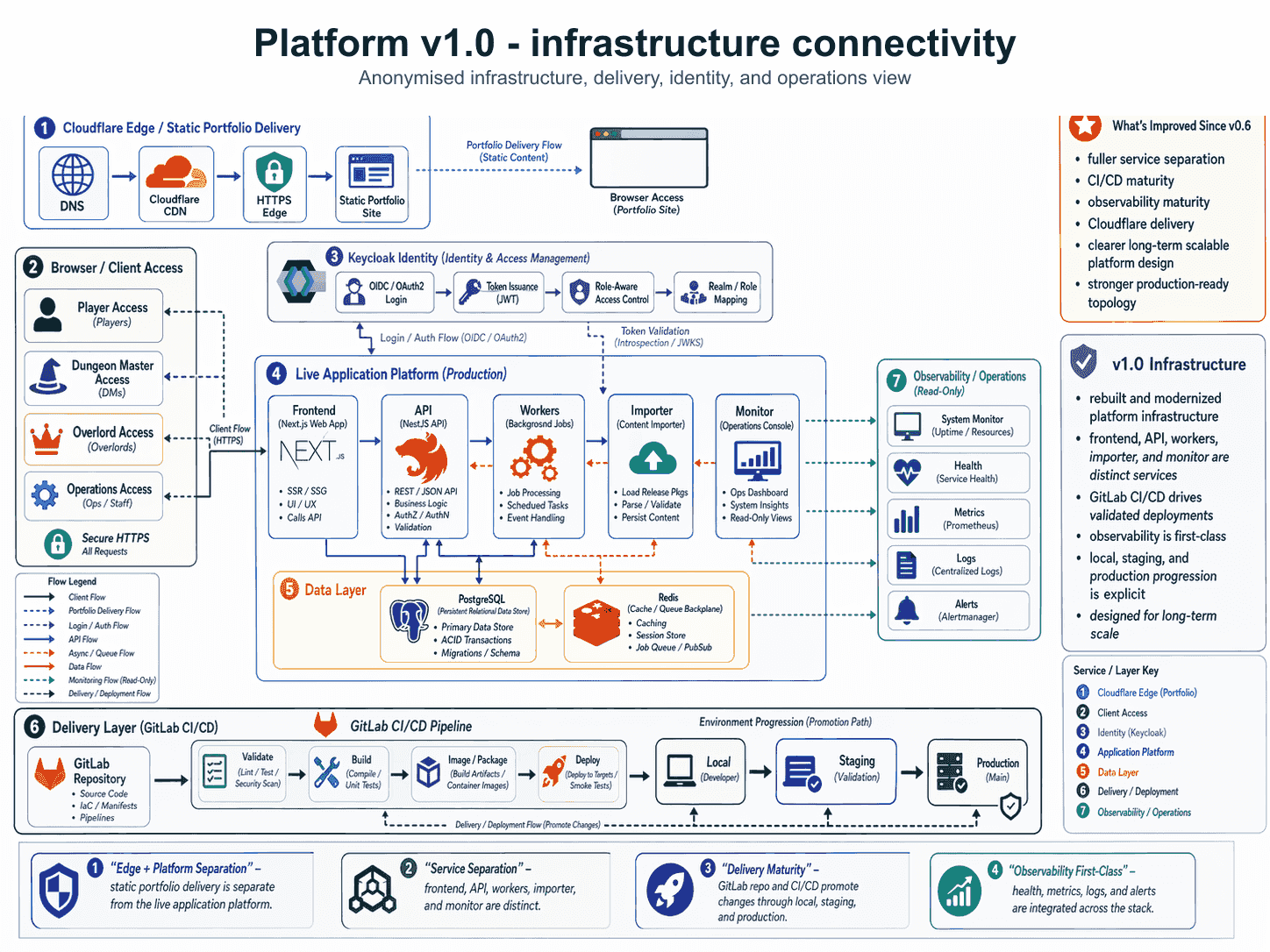
The diagram above shows the four principles as one connected map. Edge and live application surfaces sit on different platforms (Principle 1). The application platform splits into five distinct services (Principle 2). The CI/CD pipeline is part of the architecture, not a separate concern (Principle 3). Observability and operations have a labelled home in the platform, not a retrofit (Principle 4).
Principle 5: Use product-line architecture when the product spans platforms
The fifth principle comes from a different shape of build: a SaaS administration product that needed to span both Microsoft 365 and Google Workspace tenants under a single coherent product line.
The naïve approach is to build two products. One for Microsoft 365, one for Google Workspace. Same problem space, different products. The cost is roughly double — twice the codebase, twice the documentation, twice the release cadence, twice the team — and the product feels disjointed because two teams optimise for different things.
The product-line approach is structurally different. Define a shared administrative core: the dashboard, the identity surface, the policy and compliance map, the alert and incident view, the reporting layer. Above that core, define edition adapters that translate the shared abstractions to each underlying platform’s specific APIs and conventions.
The architecture splits cleanly:
- Shared frontend surface. One interface, one visual language, one interaction model. Users do not know they are using “the Microsoft edition” or “the Google edition” until the platform-specific configuration screens appear.
- Edition adapters. Each underlying platform — Microsoft 365 with Entra ID, Exchange Online, SharePoint, Teams; Google Workspace with Cloud Identity, Gmail, Drive — has an adapter that exposes the same set of operations to the shared core.
- Security and governance logic. Cross-cutting concerns — privileged access, audit, retention — live above the editions because they apply uniformly.
The pattern: shared frontend surface plus edition adapters plus shared security and governance logic. Build effort scales linearly with edition count, not multiplicatively.
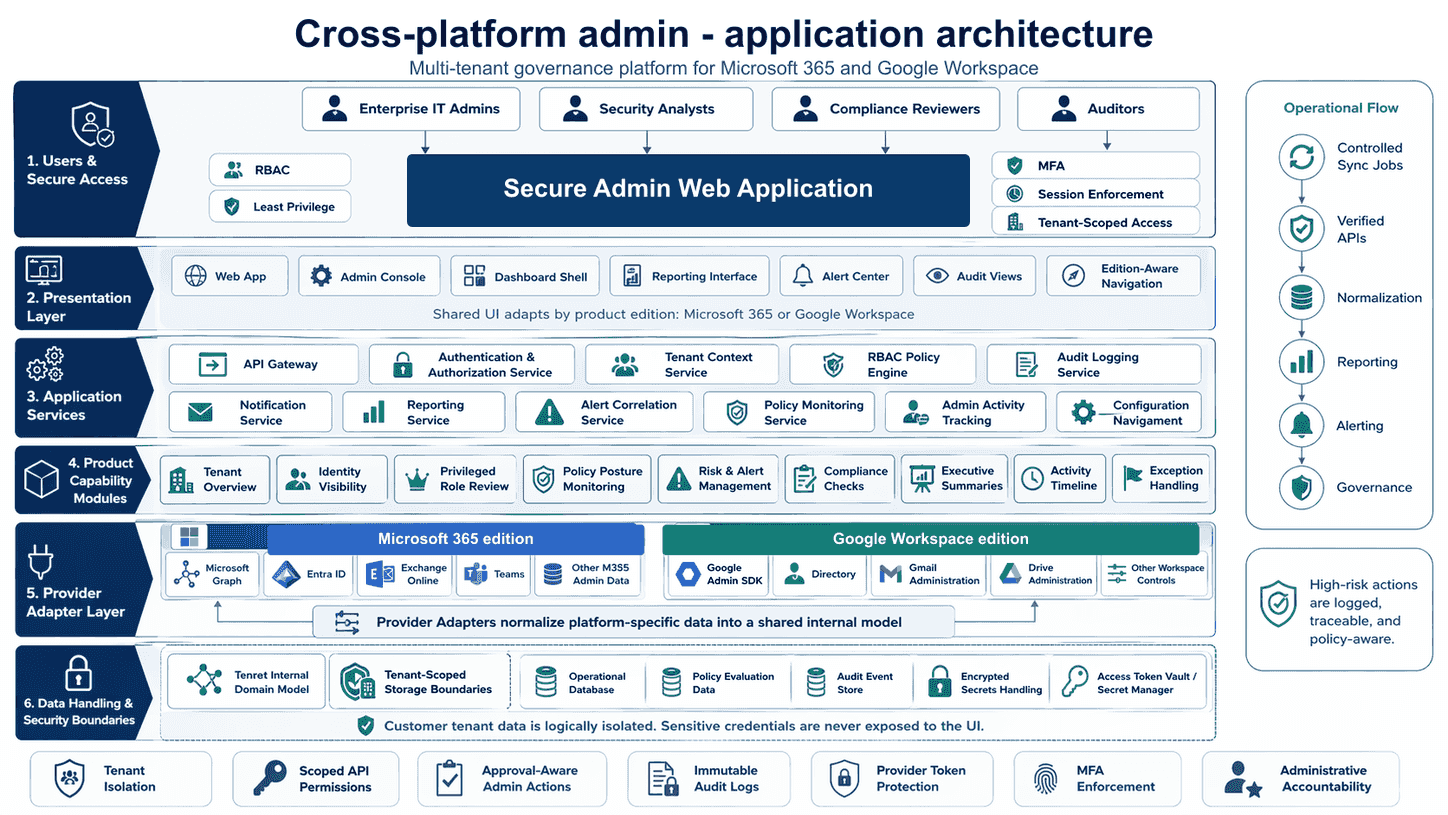
The diagram above shows the shape: one shared frontend, two edition adapters that translate to platform-specific APIs, one cross-cutting security and governance layer. The user does not see two products; the codebase does not maintain two products.
This principle generalises beyond Microsoft and Google. Any product that spans multiple underlying platforms — multi-cloud admin, multi-CRM integration, multi-payment-processor billing — benefits from the same shape.
What ties the five principles together
Each principle names a decision that has to be made early. None can be retrofitted cheaply. Each describes architecture as something that includes delivery, security, observability, and product structure — not just code.
The teams we have helped recover from sequential thinking share a common pattern. They built systems that worked, then ran into operating cost. They added DevOps to manage the cost, then ran into observability gaps. They added an SRE function to manage the gaps, then ran into architectural decisions that could not be cleanly reversed. The recovery is always architectural — the answer is not to add another team, it is to redraw the architecture map so that delivery, security, observability, and operations are in the picture.
The five principles, applied at the start, prevent that sequence.
What this looks like in practice
A few practical pointers for teams considering these principles:
- Draw the platform map early, including delivery and observability. A whiteboard with the live application services, the data layer, the identity service, the operations monitor, and the CI/CD pipeline is the right starting point — not a backlog of features.
- Pick technology after responsibility. Decide what the services are first. Then choose the runtime, the database, and the observability tools that fit those responsibilities. Reversing this order is how you end up with technology choices that the architecture does not justify.
- Embed the delivery pipeline early. The first commit should already be in a pipeline that runs the validation gates. The pipeline is allowed to be minimal initially; it is not allowed to be absent.
- Name the operations team as a stakeholder in the architecture. Even if there is no operations team yet, the role exists conceptually. The architecture map should include the operating discipline that the production system will need.
- Be honest about what is hard to change later. Identity, data layer, deployment topology, and observability boundaries are expensive to change once the platform is live. Spend more time on them at the start than feels comfortable.
Where to start
These five principles are not unique to greenfield platforms. Existing platforms can be refactored toward them — typically through a structured assessment that maps the current architecture against the principles and identifies the highest-cost gaps to address first.
This work sits in our DevOps, automation and infrastructure as code and cloud and platform engineering services. We work vendor-neutral across the major platforms and tooling — the principles are platform-independent.
Start the conversation if you would like a sounding board on a current platform or are about to start a new one.